おさらい
- LLVM
- GCCは一枚岩
GCCは再利用しにくい
- 入力がソースコード
出力がマシン語
フロントエンド(抽象構文木 ASTを作る)
- オプティマイザ(計算式を簡略化し、コードの実行時間を短縮)
- バックエンド(ターゲット上の命令セットにマップすうr)
フロントエンドとオプティマイザはCPUに非依存だが、バックエンドはCPUに依存する。
独自言語用のコンパイラを作りたいときはフロントエンドを、CPUを自作して自分のCPU用のコンパイラを作りたいときはバックエンドを自作する。
で、GCCはこの3つが綺麗に分かれていなくて、例えばフロントエンドとオプティマイザがごっちゃになっているのですべての分野についての知識が必要となるため、開発しにくい。
逆にLLVMのような3フェーズ設計だと各フェーズの実装がやりやすくなるので参入障壁は低い。
GCCのまずさは、
- グローバル変数を使いまくっている
- 不変条件の強要が齢
- データ構造の設計がまずい
などが挙げられる。
C→LLVMIR(中間コード)→アセンブラ
define i32 @add1(i32 %a, i32 %b) {
entry:
%tmp1 = add i32 %a, %b
ret i32 %tmp1
}
define i32 @add2(i32 %a, i32 %b) {
entry:
%tmp1 = icmp eq i32 %a, 0
br i1 %tmp1, label %done, label %recurse ! ここがif分岐っぽい
recurse:
%tmp2 = sub i32 %a, 1
%tmp3 = add i32 %b, 1
%tmp4 = call i32 @add2(i32 %tmp2, i32 %tmp3)
ret i32 %tmp4
done:
ret i32 %b
}
このLLVMIRの元となるコードは以下である。
unsigned add1(unsigned a, unsigned b) { return a+b; } // 非効率的な方法での足し算 unsigned add2(unsigned a, unsigned b) { if (a == 0) return b; return add2(a-1, b+1); }
MIPSと同じような感じ。
LLVM Language Reference Manual — LLVM 3.7 documentation
LLVM Language Reference Manual — LLVM 3.7 documentation
LLVMは3アドレス形式
マシン語に型はないが、LLVMIRには型がある。LLVMIRはレジスタが無限にあるけど、JVMはレジスタがなくってスタックでやろうとする。
中間コードのアーキテクチャがどうであれ、コンパイラ的にはあまり関係がなかったりする。
LLVMIRの形式
- テキスト形式(.ll)
- オプティマイザがインメモリで扱うときのデータ構造
- バイナリ形式のbitcodeフォーマット(.bc)
外部である形式を別の形式に変換するツールが存在する。
中間コードは上手に作らないといけない。
LLVMIRの最適化
無駄を省くのがオプティマイザ
- 変換できそうなパターンを探す
- 変換をしても安全か、動きが変わらないかを確かめる
- 変換を施し、コードを更新する
LLVMは高級言語ではないので、複雑な命令は複数回に分けている。
SimplifySubInst関数(上位レベルの様々な変換)
いろいろ最適化を引っ掛けてる一例。
// X - 0 -> X if (match(Op1, m_Zero())) return Op0; // X - X -> 0 if (Op0 == Op1) return Constant::getNullValue(Op0->getType()); // (X*2) - X -> X if (match(Op0, m_Mul(m_Specific(Op1), m_ConstantInt<2>()))) return Op1; … return 0; // Nothing matched, return null to indicate no transformation.
引き算のメソッド SimplifySubInst
[Sources] ./lib/Analysis/InstructionSimplify.cpp ./lib/Transforms/InstCombine/InstCombineAddSub.cpp [Headers] ./include/llvm/Analysis/InstructionSimplify.h
/// SimplifySubInst - Given operands for a Sub, see if we can /// fold the result. If not, this returns null. static Value *SimplifySubInst(Value *Op0, Value *Op1, bool isNSW, bool isNUW, const Query &Q, unsigned MaxRecurse) { if (Constant *CLHS = dyn_cast<Constant>(Op0)) if (Constant *CRHS = dyn_cast<Constant>(Op1)) { Constant *Ops[] = { CLHS, CRHS }; return ConstantFoldInstOperands(Instruction::Sub, CLHS->getType(), Ops, Q.DL, Q.TLI); } // X - undef -> undef // undef - X -> undef if (match(Op0, m_Undef()) || match(Op1, m_Undef())) return UndefValue::get(Op0->getType()); // X - 0 -> X if (match(Op1, m_Zero())) return Op0; // X - X -> 0 if (Op0 == Op1) return Constant::getNullValue(Op0->getType()); // 0 - X -> 0 if the sub is NUW. if (isNUW && match(Op0, m_Zero())) return Op0; // (X + Y) - Z -> X + (Y - Z) or Y + (X - Z) if everything simplifies. // For example, (X + Y) - Y -> X; (Y + X) - Y -> X Value *X = nullptr, *Y = nullptr, *Z = Op1; if (MaxRecurse && match(Op0, m_Add(m_Value(X), m_Value(Y)))) { // (X + Y) - Z // See if "V === Y - Z" simplifies. if (Value *V = SimplifyBinOp(Instruction::Sub, Y, Z, Q, MaxRecurse-1)) // It does! Now see if "X + V" simplifies. if (Value *W = SimplifyBinOp(Instruction::Add, X, V, Q, MaxRecurse-1)) { // It does, we successfully reassociated! ++NumReassoc; return W; } // See if "V === X - Z" simplifies. if (Value *V = SimplifyBinOp(Instruction::Sub, X, Z, Q, MaxRecurse-1)) // It does! Now see if "Y + V" simplifies. if (Value *W = SimplifyBinOp(Instruction::Add, Y, V, Q, MaxRecurse-1)) { // It does, we successfully reassociated! ++NumReassoc; return W; } } // X - (Y + Z) -> (X - Y) - Z or (X - Z) - Y if everything simplifies. // For example, X - (X + 1) -> -1 X = Op0; if (MaxRecurse && match(Op1, m_Add(m_Value(Y), m_Value(Z)))) { // X - (Y + Z) // See if "V === X - Y" simplifies. if (Value *V = SimplifyBinOp(Instruction::Sub, X, Y, Q, MaxRecurse-1)) // It does! Now see if "V - Z" simplifies. if (Value *W = SimplifyBinOp(Instruction::Sub, V, Z, Q, MaxRecurse-1)) { // It does, we successfully reassociated! ++NumReassoc; return W; } // See if "V === X - Z" simplifies. if (Value *V = SimplifyBinOp(Instruction::Sub, X, Z, Q, MaxRecurse-1)) // It does! Now see if "V - Y" simplifies. if (Value *W = SimplifyBinOp(Instruction::Sub, V, Y, Q, MaxRecurse-1)) { // It does, we successfully reassociated! ++NumReassoc; return W; } } // Z - (X - Y) -> (Z - X) + Y if everything simplifies. // For example, X - (X - Y) -> Y. Z = Op0; if (MaxRecurse && match(Op1, m_Sub(m_Value(X), m_Value(Y)))) // Z - (X - Y) // See if "V === Z - X" simplifies. if (Value *V = SimplifyBinOp(Instruction::Sub, Z, X, Q, MaxRecurse-1)) // It does! Now see if "V + Y" simplifies. if (Value *W = SimplifyBinOp(Instruction::Add, V, Y, Q, MaxRecurse-1)) { // It does, we successfully reassociated! ++NumReassoc; return W; } // trunc(X) - trunc(Y) -> trunc(X - Y) if everything simplifies. if (MaxRecurse && match(Op0, m_Trunc(m_Value(X))) && match(Op1, m_Trunc(m_Value(Y)))) if (X->getType() == Y->getType()) // See if "V === X - Y" simplifies. if (Value *V = SimplifyBinOp(Instruction::Sub, X, Y, Q, MaxRecurse-1)) // It does! Now see if "trunc V" simplifies. if (Value *W = SimplifyTruncInst(V, Op0->getType(), Q, MaxRecurse-1)) // It does, return the simplified "trunc V". return W; // Variations on GEP(base, I, ...) - GEP(base, i, ...) -> GEP(null, I-i, ...). if (match(Op0, m_PtrToInt(m_Value(X))) && match(Op1, m_PtrToInt(m_Value(Y)))) if (Constant *Result = computePointerDifference(Q.DL, X, Y)) return ConstantExpr::getIntegerCast(Result, Op0->getType(), true); // i1 sub -> xor. if (MaxRecurse && Op0->getType()->isIntegerTy(1)) if (Value *V = SimplifyXorInst(Op0, Op1, Q, MaxRecurse-1)) return V; // Threading Sub over selects and phi nodes is pointless, so don't bother. // Threading over the select in "A - select(cond, B, C)" means evaluating // "A-B" and "A-C" and seeing if they are equal; but they are equal if and // only if B and C are equal. If B and C are equal then (since we assume // that operands have already been simplified) "select(cond, B, C)" should // have been simplified to the common value of B and C already. Analysing // "A-B" and "A-C" thus gains nothing, but costs compile time. Similarly // for threading over phi nodes. return nullptr; }
ディスパッチャはふりわけをするコード。
ディスパッチャとは 【 dispatcher 】 〔 ディスパッチャー 〕 - 意味/解説/説明/定義 : IT用語辞典
11.4 LLVMでの3フェーズ設計の実装
フロントエンドからLLVMIRへ変換する
LLVM IRは完全なコード表現である
RTL(バックエンドの表現)
LLVM IRはきちんと規定されており、オプティマイザへの唯一のインターフェイスであるということ。
GCCのGIMPLE(GCCの中間表現)が自己完結していないのに比べて、LLVMは実装が分離されている。
LLVMはライブラリ群である
ライブラリ群として作られているのがよいところ。
オプティマイザはLLVMIR形式の入力を受け取って噛み砕いてLLVMIR形式を出力する。
パスはフロー。ループ内での不変なコードの移動、インライナー、式の再構成など。
最適化したら67のパスを実行するので、理論上は最適化しない場合より実行速度が67倍速い(67なのはたまたま)
名前空間が閉じられている。
namespace { class AMDGPUPromoteAlloca : public FunctionPass, public InstVisitor<AMDGPUPromoteAlloca> { static char ID; Module *Mod; const AMDGPUSubtarget &ST; int LocalMemAvailable; public: AMDGPUPromoteAlloca(const AMDGPUSubtarget &st) : FunctionPass(ID), ST(st), LocalMemAvailable(0) { } virtual bool doInitialization(Module &M); virtual bool runOnFunction(Function &F); virtual const char *getPassName() const { return "AMDGPU Promote Alloca"; } void visitAlloca(AllocaInst &I); };
ライブラリや機能が抽象化されている。
例: 架空の画像処理システムXYZ
たった一つの関数にすべてまとまっていたら必要な部分を切り出すのは面倒だけども、LLVMのオプティマイザはライブラリ設計となっているのでつまみぐいで実装しやすい。
カスタム言語のコンパイラを作る場合は、LLVMでもカバーしきれないが、既存のLLVMライブラリをつまみ食いして自分で実装することはできる、というお話。
なまら「必要ない」が繰り返されていますがおそらく誤訳です。
Since the pass subsystem is modularized and the PassManager itself doesn't know anything about the internals of the passes, the implementer is free to implement their own language-specific passes to cover for deficiencies in the LLVM optimizer or to explicit language-specific optimization opportunities.

昔ながらのコンパイラは密結合しちゃっているけど、LLVMはライブラリ化されているので、一部だけ取り出して最適化しやすい。ライブラリを組み合わせて機能を実現するのはクライアントに依存する。
CLANGは「クラン」って読む
11.5 再利用性を考慮したLLVMコードジェネレータの設計
LLVMのコードジェネレータの役割は、LLVM IRを各ターゲット向けのマシンコードに変換すること。指定したターゲット向けにいちばんいいコードを作るのがその仕事。
オプティマイザの内部処理、バックエンドの内部処理にパスが使われている。
バックエンドの作者はターゲット用のコードジェネレータをいちから書き上げる必要がない。
LLVMターゲット記述ファイル
いろいろなものを組み合わせる手法がLLVMには取り入れられている。バックエンドの作者はそのアーキテクチャに合わせた選択ができるようになる。
ターゲットごとの記述をドメイン特化言語 (.td ファイルの集まり) で提供
tblgen - Target Description To C++ Code Generator — LLVM 3.7 documentation
情報の符号化。
二つのオペランドがあるレジスターを扱う命令は、このバイトをパラメーターとしてオペコードの直後に置く。
LLVMのコードはtblgenを使って多くの情報を引き出せる。
便利な機能を提供できることだけに限らず、複数の情報をたったひとつの「正解」から生成できるということも利点。
.td ファイルで表現しきれるターゲットの量を増やすことがより重要
gccが提供しているアセンブラのことをgas(gnu assembler)という
命令の定義を.tdに書いておけばアセンブラや逆アセンブラを作りやすくなる。
なので、.tdファイルはどんどん増やしていく。
11.6 モジュラー設計がもたらす興味深い可能性
各フェーズを動かすタイミングを選ぶ
LLVM IR はバイナリ形式 (LLVM ビットコード) との間でのフォーマット変換ができる
Link-Time Optimization リンク時にも最適化しようという試み。複数のファイルをリンクするときに、複数のファイルにまたがって最適化できるようになった。
bitcode + bitcode = native code リンクするときにネイティブコードにするからバックエンドが動くのはリンクしたあと。
Interprocedural optimization - Wikipedia, the free encyclopedia

LLVM の場合は、システムの設計からごく自然に LTO が実現できる。(他のコンパイラだとつらい)
インストール時の最適化とは、コードの生成をリンク時よりもさらに先延ばしにして、インストールのときに行うというものだ
c++ - llvm and install time optimization - Stack Overflow

オプティマイザのユニットテスト
オプティマイザでクラッシュを引き起こすようなバグを修正したとしたら、同じバグが再発しないようにリグレッションテストも追加しないといけない
他のコンパイラは密結合になってしまっているので、フロントエンドやオプティマイザの初期段階で何かを変更すると、これまでのテストケースが動かなくなりやすい
リグレッションテストとは 〔 回帰テスト 〕 〔 レグレッションテスト 〕 - 意味/解説/説明/定義 : IT用語辞典
LLVM IR のテキスト形式とモジュール式のオプティマイザを使うことで、LLVM のテストスイートはリグレッションテストに注力できるようになる。
a = 4 + 5→a = 9に最適化されているかどうかを確認するテスト。コメント行がアノテーションぽく書かれているので若干気持ち悪い書き方である。
; RUN: opt < %s -constprop -S | FileCheck %s define i32 @test() { %A = add i32 4, 5 ret i32 %A ; CHECK: @test() ; CHECK: ret i32 9 }
define i32 @test() {
%A = add i32 4, 5
ret i32 %A
}
%Aが9であるかどうかのテストではなく、ret i32 9に最適化されているかどうかのテスト。
LLVM Testing Infrastructure Guide — LLVM 3.7 documentation
; RUN: opt < %s -instsimplify -S | FileCheck %s
define i1 @add(i1 %x) {
; CHECK-LABEL: @add(
%z = add i1 %x, %x
ret i1 %z
; CHECK: ret i1 false
}
define i1 @sub(i1 %x) {
; CHECK-LABEL: @sub(
%z = sub i1 false, %x
ret i1 %z
; CHECK: ret i1 %x
}
define i1 @mul(i1 %x) {
; CHECK-LABEL: @mul(
%z = mul i1 %x, %x
ret i1 %z
; CHECK: ret i1 %x
}
define i1 @ne(i1 %x) {
; CHECK-LABEL: @ne(
%z = icmp ne i1 %x, 0
ret i1 %z
; CHECK: ret i1 %x
}
LLVMだと直感的にテストしやすい。
BugPoint による、自動的なテストケースの単純化
コンパイラ、あるいは LLVM のライブラリを使う他のクライアントに何らかのバグが見つかったとして、それを修正するためにまず最初にすることは、問題を再現するためのテストケースを書くことだ
Delta Debuggingの紹介 | SourceForge.JP Magazine
手作業だとつらいのを自動化するデバッグ方法。
Delta Debugging - Lehrstuhl für Softwaretechnik (Prof. Zeller) - Universität des Saarlandes
デルタデバッギングの手法
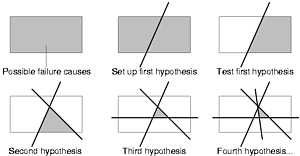
LLVMもデルタデバッギングと似たテクニックで、入力と最適化パスのリストを減らしていく。それがBugPoint
場当たり的に拡張されてきたのがBugPointで、デルタデバッギングと似た手法がとられている、っていう話。
11.7 ふりかえりと今後の方針
LLVMはしょっちゅうAPIが変わってた。それも互換性を無視して。そういうことをやっていくことで、LLVMを軽量なまま保ち続けることに成功した。
LLVMの中の人もAppleなので、クライアントを無視して開発を進めるのは伝統芸能っぽい。故に初期のクライアントは本当に人柱っぽかった。
今後の展望としては、LLVM をもっとモジュール化して、サブセットを作りやすいようにし続けていきたい。って書いてある。
SwiftだとLLDBがまともに動かない。Objective-Cのときは結構スムーズに使える。
16 Selenium WebDriver
Selenium はブラウザの自動化ツールで、ウェブアプリケーションのエンドツーエンドテストを書くときによく使われる。ブラウザの自動化ツールが行うのは、その名前から想像できるとおりのことだ。ブラウザを制御して、繰り返し行われるタスクを自動化できる。解決しようとしている問題は単純なものだが、本章で説明するとおり、その裏側ではさまざまなことが起こっている。
Selenium WebDriver のアーキテクチャを取り扱う。
16.1 歴史
もともとJavaScriptの自社製品をテストしたい目的で作った。
Selenium (software) - Wikipedia, the free encyclopedia
はっきり言って、人はくだらない繰り返し作業をするのが苦手だ。機械に比べて能率も悪いし間違いも多い。手動でのテストも選択肢から消えた。
テストを手作業でやるのが面倒なので、自動化したいっていう願望。
このプロキシを使えば、“同一生成元ポリシー” の制約の多くを回避できるようになった。このポリシーは、Javascriptからそのページを提供するサーバー以外への呼び出しを許可しないというものである。これを回避できたことで、最初の弱点は何とかしのげるようになった
Seleniumの問題から、プロキシを作った。そのプロキシから本当のテストを叩く。
ユーザーから見たときの最大の相違点は、Selenium RC は辞書ベースの API ですべてのメソッドを単一のクラスで公開しているのに対して WebDriver はよりオブジェクト指向な API を提供していることだった。
2009/8に2つのプロジェクトが合流し、いろいろな言語をサポートするようになった。
AndroidDriver - selenium - Browser automation framework - Google Project Hosting
Selendroid: Selenium for Android
いろいろ出ているけど、仕様がちょくちょく変わるので、あまり使いたくないユーザーもいたりはする。
16.2 ジャーゴンについての余談
Seleniumプロジェクトにはジャーゴンが氾濫している。独自用語が氾濫しすぎてわけがわからない。
ジャーゴン【jargon】の意味 - 国語辞書 - goo辞書
- ドライバ WebDriver API の特定の実装を指す名前
- 「Selenium」が何を表すのかは話の流れで明確になることが多い
16.3 アーキテクチャについて
- コストを抑える。
- ユーザーをエミュレートする(WebDriver は、ユーザーがウェブアプリケーションとやりとりする内容をそのまま正確にシミュレートするように作られている)
- ドライバが動作することを実証する(ある意味理想主義的かもしれないが、動作しないコードなどまったく無意味である。ので、様々なプラットフォームで多くのテストを実行できるようにするようSeleniumのテストを書き続けている)
- が、それがどのように動作するのかを知る必要はないようにする(Seleniumを作る場合のはなしで、全部を知らなくてもAndroid用のSeleniumを作ることはできる)
- バス係数を上げる(その人が死んだらプロジェクトが動かなくなる係数のこと。Seleniumはそれを増やす)
- Javascript の実装を尊重する(Javaとかで裏側で何かするのではなく、純粋なJavaScriptでの開発をやる。JDBCへのアクセスがうまくいかない可能性があるので、JavaScriptを使うようにした)
- すべてのメソッドコールは RPC である。
- 我々は、オープンソースプロジェクトである。
インテグレーションテスト(結合テスト) ユニットテスト(単体テスト)
ユニットテストは書くけどインテグレーションテストはあんまり書かないかもね。
具体的な実装が全く良くわからないぞ。
RPC - Wikipedia 他のプロセスに対して操作を行うこと。WebDriverがブラウザのプロセスに対して操作する。
具体的にはこんな感じ。
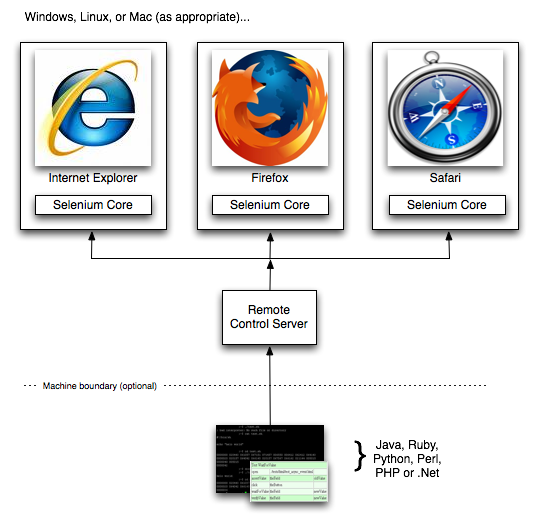
レイテンシと使いやすさのバランスは重要。
結論: オープンソースです
参加するために必要な知識をできるだけ抑え、知っていてほしい言語の数も最小にして、さらに自動テストを活用して何も壊さないことを確かめる。これらはすべて、新規参入を促すのが狙いである。
言語ごとにディレクトリ構造を変えたら、開発者が増えた。
16.4 複雑性への対応
ソフトウェアは、こぶだらけででこぼこな構造である。その原因は複雑性であり、API を設計する側の立場で考えると、その複雑性をどこに押し込めるかを判断しなければならない。
APIの複雑さをまんべんなく広げる vs 一箇所に隔離する
合成イベントとは(ゲームとは関係ない)
JavaScriptでイベントをエミュレートする(From Kanasan.JS 読書会#8) | Blog.37to.net
WebDriver の設計
開発チームでは、WebDriverのAPIがオブジェクトベース(インターフェイスを明確に定義して単一のロールあるいは責務だけを受け持たせようとする)であるよう心がけている。
IDEの補完機能に頼れば楽に開発ができるよってはなし。
Abstract Window Toolkit - Wikipedia
切り分けして影響力を少なめに。
組み合わせの激増への対処
対応する言語とブラウザを増やすと組み合わせ爆発がやばいけど、対応するブラウザを減らすという選択肢は取らなかった。各言語のバインディングから、すべてのブラウザを同じように扱えるようにする方法をとった。
統一形式のインターフェイスを用意し、さまざまな言語から容易にアクセスできるようにすること。
統一部分はドライバ本体のロジックに押しこむようにした。
WebDriver の設計の問題点
Seleniumの機能がユーザーに気づかれにくい欠点があったので、ドキュメントづくりに力を注いだ。
RenderedWebElementはいろいろなメソッドがごちゃまぜになっていて汚いAPIになっている。
ゴッドクラスになりがちなので、こういうのは割れ窓的にどうにかしないといけない。
16.5 レイヤーと Javascript
自動化の構成。
- DOM への問い合わせ手段。
- Javascript を実行する仕組み。
- ユーザーの入力をエミュレートする何らかの手段。
階層構造になっているようである。

Closure Tools — Google Developers
Closure Libraryを使っているのは、Seleniumと相性がよく、詳しい人が何人もいたから。
属性をとってきたり操作をシュミレートしたりする部分がatoms層
権限の昇格(JavaScriptの開発だとルート権限がいらない?)
Atoms.js - Enterprise Grade JavaScript Web Components inspired from Flex & Silverlight
自前で作ってレイヤーを抽象化する。
atomsを使う利点
- バス係数を上げる
- エミュレートレイヤーを正確に書ける
atomsを使うデメリット
- Javascript をコンパイルして C の定数にしてしまうという奇妙な作業(constって書くと文字列になる jarにリソース)
- ブラウザごとの返り値を正規化するので、予期せぬ値が返ってくることもあり得る
- 正規化したら個別に作っている人に影響が出た
このあたりはJavaScriptの闇っぽい
中のことが延々と書いてある。